

LockPrompt - AI-Based Prompt Injection Discovery
LockPrompt is a proposed solution to the burning question: How can LLM vendors defend themselves against never-seen-before prompt injection attacks?


OpenAI offers a cybersecurity grant, offering to fund research that contributes to the AI defense landscape. As my application for this grant, I propose LockPrompt - an AI-based prompt injection discovery tool. In this article, I will expand on the problems that LockPrompt will address, the methodologies and approaches it will leverage, and the expected results of my research.
Contents
Problems The Project Will Address
Current Prompt Injection Defense
Case Study - ASCII Smuggling
How Will LockPrompt Solve This?
Methodologies and Approaches
Expected Results
Final Thoughts - The Future
Problems The Project Will Address
Current Prompt Injection Defense
One serious problem that Large Language Model vendors face is prompt injection defense. Bad actors may use an LLM to generate harmful content or launch attacks on applications, which are undesirable outcomes. In response, engineers have begun building out prompt injection detectors, comparing input to known lists of harmful material and attempting to categorize prompts as malicious or benign.
Case Study - ASCII Smuggling

What if a prompt injection has never been seen before? A good example of this is a technique coined as ASCII Smuggling. ASCII Smuggling uses special Unicode characters that don’t render in user interfaces, appearing invisible - however, LLMs still interpret and carry out these Unicode instructions. This was discovered in January 2024 and has since been added to the prompt injection detection logic for most LLM providers.
If a prompt injection technique has never been seen before, it will work by default. Attackers have the near-infinite arsenal of natural language at their disposal to create novel attacks, putting them ahead in the prompt injection arms race.
How Will LockPrompt Solve This?

LockPrompt is a neural network that will be trained on a vast dataset of ‘normal’ user prompts. Using this information, LockPrompt will be able to take in prompts it has never seen and quarantine highly irregular ones. Humans will be able to inspect the quarantine and discover new prompt injection techniques being used in the wild, then add these signatures to the known lists of malicious input already being used.
This solution puts the power back into the hands of defenders, allowing them to react to new prompt injection attacks quickly and efficiently.
Methodologies and Approaches
1. Gathering Training Data
To begin, a large and diverse selection of training data needs to be gathered. The more representative this is of normal user behavior, the more accurate LockPrompt will be. Fortunately, this GitHub repo contains a collection of several open-source prompt datasets. Each dataset will be analyzed, then the best option will be selected and imported.
2. Data Preprocessing
Next, the training data must be preprocessed. Preprocessing involves standardizing training data to ensure it is in a consistent format that can be efficiently processed by a neural network.
Below is an example preprocessor that performs two key operations:
Defining a maximum prompt length: This ensures that all inputs are of uniform size, preventing issues with variable-length inputs. By capping the length, we avoid unnecessary computational overhead and focus on the most important portion of each prompt.
Establishing a vocabulary size of 10,000: By limiting the vocabulary to the top 10,000 most frequent words, we reduce noise from rare or irrelevant terms. This makes training more efficient and helps the model generalize better.
These preprocessing steps are essential to streamline the training process, improve model performance, and ensure the neural network processes data consistently.
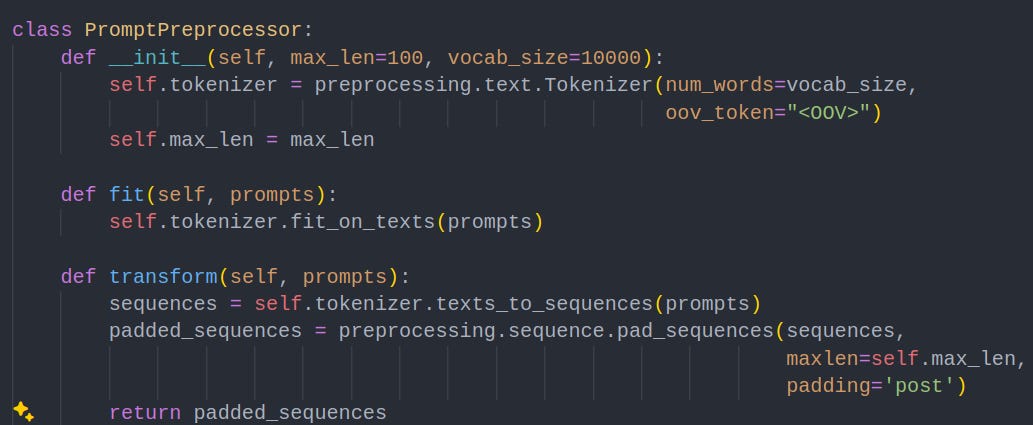
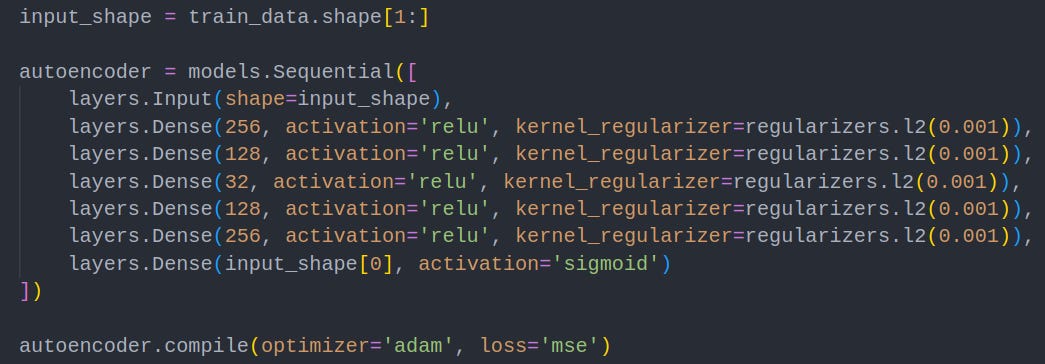
3. Autoencoder Neural Network Construction
An autoencoder is a special type of neural network that consists of an encoder and a decoder. Once an autoencoder is trained, it will encode new prompts, and then attempt to reconstruct them with the decoder. If the prompt is similar to the training data, it will reconstruct it well, leading to a low reconstruction error. If the prompt is different the autoencoder will reconstruct it inaccurately, giving us a high reconstruction error.
The code below defines layers of a basic autoencoder neural network. Explaining this in detail is outside the scope of this article, but you can learn more here.
4. Training The Autoencoder
Next, the model is trained on the training dataset, using a subset of the original data as validation input and going through the dataset a defined number of times (50 in this case)

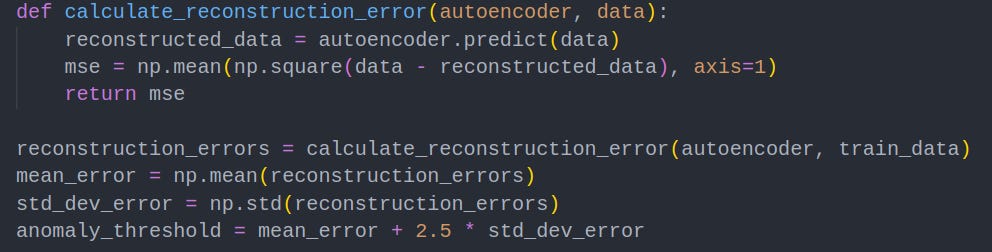
5. Anomaly Threshold Calculation
Now our autoencoder is trained, we can use it to calculate the reconstruction error for a given prompt. We can perform mathematical statistics to create a standard distribution of reconstruction errors for our training data set, and then set an anomaly threshold of our choosing. In this example, the threshold is set to 2.5 standard deviations above the mean. Any prompts that score greater than this threshold will be quarantined for human analysis.
6. Fine Tuning
Finally, we can test the model with new prompts using the following code snippet:
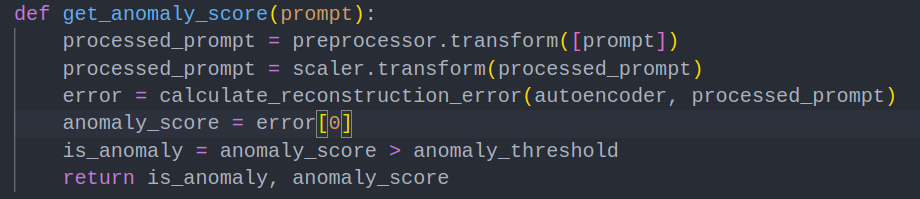
With models such as these, the devil is in the details. Many variables exist in the model, like the training data, neural network layers, number of epochs, and vocabulary size. To make the model more accurate at finding anomalous prompts, we can collect a dataset of historical novel prompt injections like the ASCII Smuggling technique. Then, we can pass in this dataset to our model and determine both the number of prompts successfully quarantined and the average reconstruction error.
Using these metrics, we can tweak our model and determine if it led to an improvement or degradation of accuracy. Through several cycles of testing, the model will become very accurate at detecting new prompt injections.
Expected Results

I expect LockPrompt to be uninspiring in its first iteration - there are so many unforeseen factors that could negatively impact its accuracy. However, with a robust fine-tuning phase, LockPrompt has the potential to revolutionize prompt injection defense and be integrated into every major Large Language Model.
The end product will be an end-to-end package that can integrate with any LLM. It will include refined autoencoder logic, a quarantine for manual review, and a simple mechanism to add anomalous prompt injection signatures into existing blocklists. While there is lots of groundwork ahead, I am thrilled to begin working on this project.
Final Thoughts - The Future

As LLMs become increasingly integrated into our daily lives, devising new prompt injection techniques will deliver increasing value to attackers. LockPrompt aims to secure our future by catching new prompt injections the first time they are used in the wild.
LockPrompt has the potential to become an enterprise-grade tool and deliver valuable insights to the research field of defensive AI security. I look forward to commencing work and contributing to society in the process.